


AI Hallucinating and FOIA
Speculating on using FOIA processing failure metrics

Background
A few weeks ago I posted about the State Department using a MITRE-built AI prototype, dubbed FOIA Assistant, designed to find records in government datasets and recommend redactions. The details were sparse. However, one added tidbit I found was that MITRE FOIA Assistant uses the open-source software library spaCy to detect personally identifiable information in public documents.
We considered using spaCy a year or two ago at the City of Seattle, and according to reviews the library has made huge gains because they’ve incorporated multi-task learning with pre-trained transformers. The Medium article cites as example that spaCy added BERT, which makes sense, so consider this another plug for my interest.
One thing I didn’t note in the State Department’s slides (but was brought up in the comments) was the apparent lack of clear metrics. There were some stated “goals,” but of the exploratory kind. The State Department wanted to explore how well the AI performed at identifying PII for reviewers. However, is well-performing a failure rate of 1%? 10%? No failures?
With this in mind I created my own scenario for ChatGPT to get a sense of what makes sense as a metric. I legitimately believe that there is no substitute for tinkering and moving things from the category of ‘that sounds right’ to the second category of ‘look at these facts.’

As I thought about what AI failure looks like I have noted an uptick in AI related content (perhaps as proof that the algorithm is always watching)
For example, I recently learned that Michael Cohen, Trump’s fixer, is an avid if unskilled user of generative AI. In an unsealed court letter from Michael Cohen in the Southern District of New York, Cohen’s lawyer explained why he should not be sanctioned for citing in his (Cohen’s attorney’s) motion cases that appear not to exist. Apparently, Cohen found some cites and his attorney relied on them without checking.
Cohen’s letter explained that he was under the impression that Google Bard was a “super-charged search engine,” rather than an AI program, and that the AI’s hallucinatory citations were real citations.1
The District Court goes on to explain,

No harm, no foul.
A more serious matter was in the same district but not same court two weeks ago. Two New York lawyers submitted a legal brief that included six fictitious case citations generated by ChatGPT. There the District Court ordered the lawyers to pay a $5,000 fine, found the lawyers acted in bad faith and made "acts of conscious avoidance and false and misleading statements to the court." Here is a source via the legal brief.

Last but not least, another example of AI making up legal cites in Mata v. Avianca Airlines - Affidavit in Opposition to Motion - DocumentCloud.
However, as fun as these examples are to talk about the underlying premise of hallucinated cites doesn’t necessarily speak to FOIA processing. What I’d like to see is an example of what a failure metric would be if applied to a FOIA-processing task.
FOIA and ChatGPT
In FOIA processing an essential but unloved task is preliminarily identifying a sensitive document and appropriately coding the document for second-line review.
With that in mind I created a scenario for ChatGPT. The use case I imagined was initially elaborate. I wanted ChatGPT to scan text for someone asking someone else to get on the phone. When someone tells someone they need to get on the phone, perhaps what they are about to say is stuff they don’t want to be in writing. See, for example, Google.

For lack of a better idea, I found an ipsum generator, created a bunch of text and then threw in among the gibberish the phrases I wanted ChatGPT to find. I then divided the text up into “Document 1,” “Document 2,” etc. I wanted the language model to find possible permutations of “Pick up the phone” and say what paragraph (aka “Document”) the phrase appeared in.
However, ChatGPT did not find the text unless I told it specifically the exact text to find. ChatGPT was maximally no more useful than “ctrl + f.”
For example, I told the language model to find phrases that started with “P,” were 14 letters in total, and were similar to “Pick up the phone.” The expected result was “pick the phone up,” “pickup the phone,” and “phoning in a call,” which were all phrases I put in the fake text.
I did not care about any additional phrases because I could add further prompts to narrow down the language list ChatGPT created. Afterall, if ChatGPT picked up on “pick up the [OBJECT],” as long as that fit the criteria then that would simply be more proof of success.
No luck. What I got was actual gibberish.
I backtracked my prompts and started from the beginning. Instead of asking ChatGPT to find these phrases, I asked it to first simply create the phrases. The hope was to then match these up. Call it “ctrl + f, but better.”
What I discovered was that ChatGPT is really bad at that too.
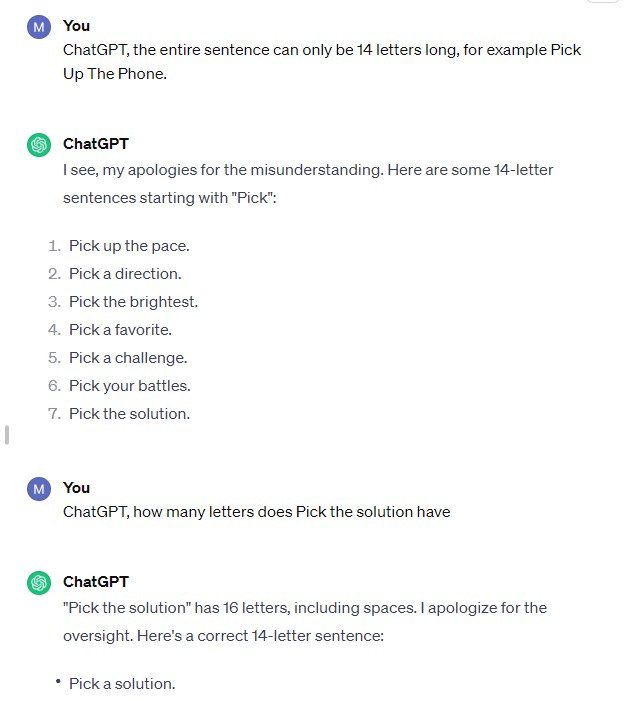
The answer does explain why ChatGPT was giving me so much lorem ipsum gibberish. The language model had difficulty identifying 14-letter sentences as 14-letter sentences.
Eventually, when nothing else worked, I said it had to start with “pick.” I was simply trying to get some proof that it could spit out “pick the phone up.” It never happened.
At one point I felt like I was going crazy, so I asked ChatGPT a crossword question where the answer was pickup the phone. 14 letters, “exasperated cry for voicemail,” etc.
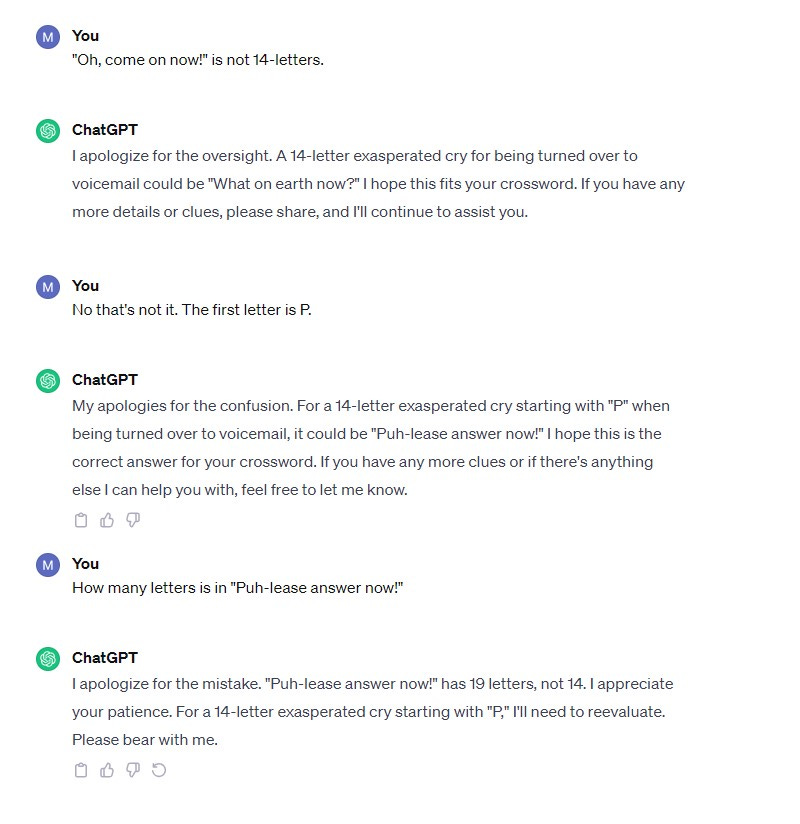
All to say, I’m not sure I was left with confidence. I am not sure how FOIA processing with the help of a language model like ChatGPT would work if ChatGPT says 15 letters or 13 letters are 14 letters.
Ironically, in terms of metrics, I could see valuable insights about ChatGPT’s own failures coming from ChatGPT. When I queried ChatGPT about the list of possible phrases that did not fit the criteria, ChatGPT was quick to identify its own failings. As applied to the State Department, I could see a metric based on how many times the generative AI found that it, the AI, failed, which is a little mind bendy.
More importantly, I could see how ChatGPT is useful in rapidly going through a lot of text if someone has, like with BERT, carefully crafted an exhaustive library of potential PII and then the PII is brought forward to a reviewer’s attention. As a metric, ChatGPT could tell me rapidly how much text it had reviewed and how many phrases it used to search through the text.
As the last metric implies, the reason I am not fully satisfied with the BERT answer is because BERT is hardly AI, no matter how well used.
For consideration, however, Jonathan H. Choi, Amy Monahan, and Daniel Schwarcz from the University of Minnesota have recently turned their attention to their own experiment on AI.
We found that access to GPT-4 slightly and inconsistently improved the quality of participants’ legal analysis but induced large and consistent increases in speed. The benefits of AI assistance were not evenly distributed: in the tasks on which AI was the most useful, it was significantly more useful to lower-skilled participants. On the other hand, AI assistance reduced the amount of time that participants took to complete the tasks roughly uniformly regardless of their baseline speed. In follow up surveys, we found that participants reported increased satisfaction from using AI to complete legal tasks and that they correctly predicted the tasks for which GPT-4 would be most helpful.
I also provide a copy here, which I got from the authors for free.
Embrace debate! They find that AI assistance is definitely useful.
My read of the paper buys the takeaways given my anecdotal experiment. ChatGPT could do tasks much faster than I could — even if the answers weren’t always right. The benefit to me (i.e., the study’s fictional GPA) is self-evident. The caveat, however, is that I had to have a good premise going into the task. If I didn’t know what I was talking about, or if I did not look very closely at what ChatGPT produced, then the whole process goes off the rails.
But that’s enough poisoning the well! Please go check out the study! And that’s all I had for this midweek update.
Even though the topic is not strictly FOIA, the topic of disclosure does pop up. (The algorithm was on its A-game.) The District Court's Order to Show Cause was accompanied by a letter-motion to seal Cohen’s response. In the letter-motion, Cohen’s lawyer said the Order to Show Cause “implicates the confidentiality of the attorney-client privilege.” Cohen’s lawyer asked for the seal until the District Court resolved “whether Mr. Schwartz can reveal the information stated in his affirmation without violating the attorney-client privilege.”
Sounds like an example of AI slowing things down as opposed to making life easier. The court sounded very sure that there was no wrongdoing. It is reasonable to believe that as they had an explanation, but still...you never know!
“Hallucinated cites” 😂